En esta entrada voy a tratar de explicar las nociones básicas que debemos tener en Linux para su administración, desde cómo gestionar usuarios hasta cómo programar tareas
1. Administración de usuarios y grupos
1.1 Creación de usuarios y grupos
Para administrar las cuentas de usuarios y las cuentas de grupos, debemos ser superusuario (root). Con ello podremos gestionar la pertenencia de los usuarios a los grupos y la eliminación de usuarios que no sean necesarios.
1.1.1 Creación de nuevos usuarios
Mientras que en Windows hay un grupo "Usuarios" que es donde por defecto se van introduciendo los nuevos usuarios, en Linux cada vez que creemos un usuario, se creará un grupo con el mismo nombre en el que será incluido inicialmente (y será su grupo principal).
Con el comando "adduser" creamos un usuario, por ejemplo "adduser Manuel"crearía el usuario "Manuel". Además, como hemos comentado, se crearía el grupo "Manuel" y se incluiría en el este usuario que hemos creado.
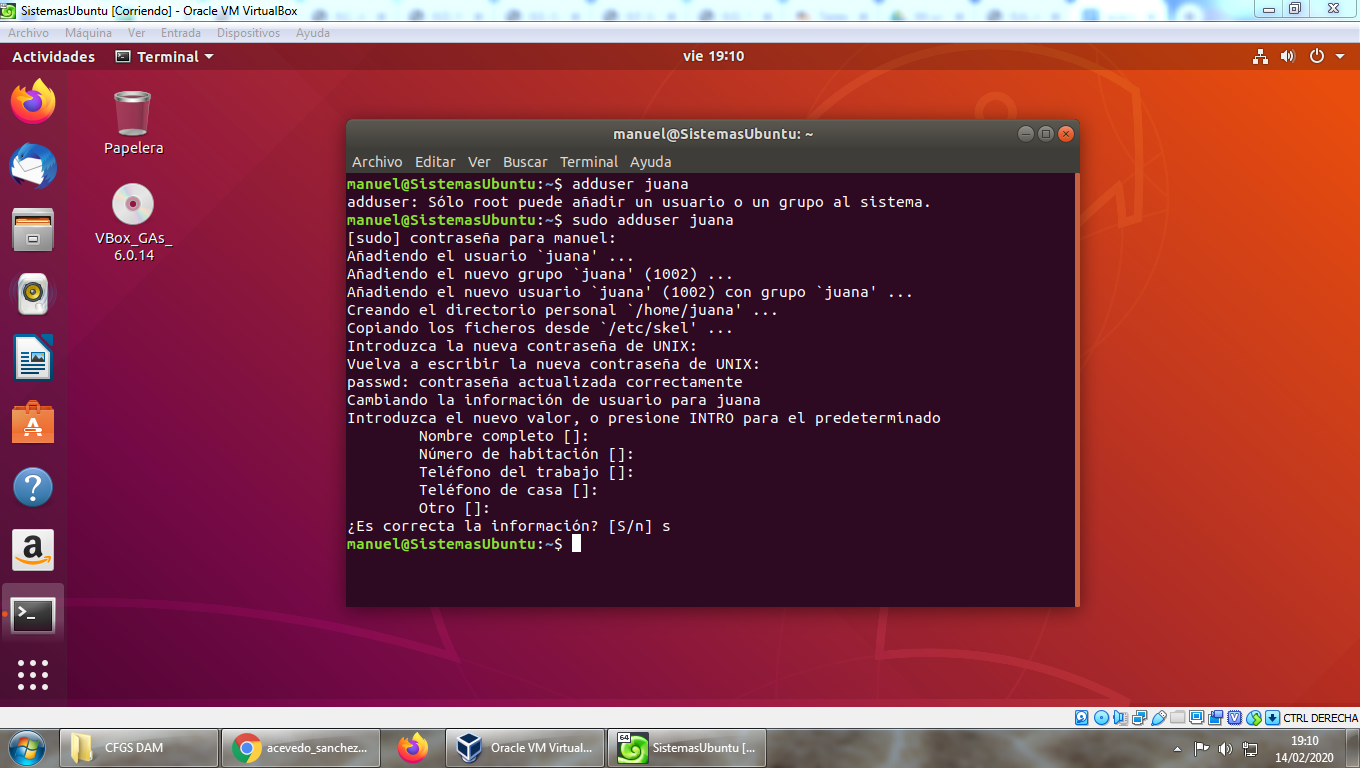
Realmente, se llevan a cabo tres acciones empleando este comando.
Si probamos en Ubuntu, podemos usar "adduser" o "useradd". La diferencia reside en que "adduser" es más completo porque por ejemplo, crea el directorio "HOM". En otras distribuciones de Linux como Red Hat, sucede al contrario.
Si hiciésemos la prueba en el prompt (shell) del sistema, obtendríamos:
manuel@aprenDAMdesarrollo:~$ sudo adduser Manuel
[sudo] password for manuel: (introducimos nuestra contraseña inicial, la de "manuel" en mi caso que sería el usuario que creé cuando instalé Ubuntu)
Añadiendo el usuario `Manuel' ...
Añadiendo el nuevo grupo `Manuel' (1004) ...
Añadiendo el nuevo usuario `Manuel' (1004) con grupo `Manuel' ...
Creando el directorio personal `/home/Manuel' ...
...
[sudo] password for manuel: (introducimos nuestra contraseña inicial, la de "manuel" en mi caso que sería el usuario que creé cuando instalé Ubuntu)
Añadiendo el usuario `Manuel' ...
Añadiendo el nuevo grupo `Manuel' (1004) ...
Añadiendo el nuevo usuario `Manuel' (1004) con grupo `Manuel' ...
Creando el directorio personal `/home/Manuel' ...
...
En verde observamos las líneas devueltas por la máquina tras ejecutar el comando en negro ("sudo adduser Manuel"). En rojo, mis comentarios.
1.1.1 Creación de nuevos grupos e introducción de usuarios
Para crear un nuevo grupo, emplearemos el comando "addgroup" (addgroup nombre_grupo), que lo creará con el nombre que le asignemos a continuación de la instrucción.
Si queremos crear un usuario nuevo dentro de un grupo existente, emplearemos el comando:
adduser nombre_usuario --ingroup nombre_grupo
Por ejemplo, si queremos crear los usuarios Virginia y Mercedes en el grupo Amigos, deberíamos ejecutar los comandos:
sudo addgroup Amigos
sudo adduser Virginia --ingroup Amigos
sudo adduser Mercedes --ingroup Amigos
Este ejemplo lo podríamos hacer también pasando a superusuario esribiendo primero "sudo su", añadiendo las líneas sin "sudo" y posteriormente, saliendo de superusuario escribiendo "exit" (para salir de superusuario).

Para modificar la contraseña de un usuario, tendremos que hacerlo desde la cuenta de dicho usuario o desde la cuenta de superusuario. En este caso, emplearíamos el comando:
passwd nombre_usuario
Al ejecutar, tendremos que introducir y confirmar la contraseña, es decir, escribirla dos veces.
1.1.2 Ficheros empleados
Cuando creamos nuevos usuarios y grupos, estamos escribiendo información en varios ficheros distintos:
El fichero /etc/passwd contiene una línea con cada usuario.
El fichero /etc/shadow contiene las contraseñas encriptadas de cada usuario.
El fichero /etc/group contiene una línea con cada grupo existente.
El fichero /etc/passwd contiene una línea por cada usuario, apareciendo varios usuarios más de los que hemos creado puesto que hay servicios que tienen usuarios asignados.
Si ejecutásemos el comando "cat /etc/passwd", comprobaríamos los usuarios registrados apareciendo en primer lugar el superusuario (root) y además de los usuarios normales, los de servicios como "mail":
manuel@aprenDAMdesarrollo:~$ cat /etc/passwd
root:x:0:0:root:/root:/bin/bash Superusuario
mail:x:8:8:mail:/var/mail:/usr/sbin/nologin Usuario del servicio de correo
…....................................
manuel:x:1000:1000:miguel,,,:/home/manuel:/bin/bash
alumno:x:1001:1001:,,,:/home/manuel:/bin/bash
manuel:x:1002:1002:Manuel AS,,3214556987,:/home/Manuel:/bin/bash Usuario creado
Virginia:x:1003:1003:,,,:/home/Virginia:/bin/bash
Mercedes:x:1004:1003:Mercedes CR,,123456789,:/home/Mercedes:/bin/bash Usuario creado
Podemos comprobar que hay varios campos separados por ":". Estos siete campos representan:
1º Nombre de usuario (Virginia).
2º Símbolo que determina un usuario habilitado o no, en este caso vemos una "x", que quiere decir que el usuario está habilitado y su contraseña se encuentra encriptada.
3º UID (identificador de usuario) único para cada usuario. El superusuario tiene UID 0, por lo que siempre aparece en primera línea.
4º GID (identificador de grupo), que determina cuál es el grupo principal del usuario. Recordemos que un usuario puede pertenecer a varios grupos: este sería el principal.
5º Datos descriptivos del usuario, que habremos introducido al registrarlo (Mercedes CR,, 123456789).
6º Directorio $HOME del usuario (/home/Manuel)
7º Shell que usa por defecto el usuario. En la mayoría de distribuciones Linux suele ser la Bourne Again Shel (BASH).
Si nos fijamos, en el caso del usuario "mail" (servicio) aparece "nologin". Esto quiere decir que este usuario es sólo para uso del servicio correspondiente (en este caso, el servicio de correo), por lo que no podremos utilizarlo para inicio de sesión.
El fichero /etc/group tiene registradas tantas líneas como grupos existentes haya. Si queremos consultarlos, haremos uso del comando "cat /etc/group". Una posible salida de terminal para este comando sería:
root:x:0:
manuel:x:1000:
familia:x:1001:padre, madre:
virginia:x:1002:
mercedes:x:1003:
manuel:x:1000:
familia:x:1001:padre, madre:
virginia:x:1002:
mercedes:x:1003:
Podemos comprobar cuatro campos separados por ":", que son:
1º Nombre del grupo.
2º Grupo habilitado (x).
3º GID (identificador del grupo).
4º Usuarios que pertenecen de forma secundaria a este grupo. En caso de que en el grupo tan sólo haya un usuario, no aparecería información en esta parte.
2º Grupo habilitado (x).
3º GID (identificador del grupo).
4º Usuarios que pertenecen de forma secundaria a este grupo. En caso de que en el grupo tan sólo haya un usuario, no aparecería información en esta parte.
2. Eliminación y modificación de usuarios y grupos
2.1 Creación de usuarios y grupos
Para eliminar un usuario usaremos el comando "userdel", de este modo:
#userdel Manuel eliminaría el usuario "Manuel"
#userdel Manuel -r eliminaría el usuario "Manuel" y su directorio $HOME (/home/Manuel)
Para eliminar un grupo usaremos el comando "groupdel" si el grupo está vacío (no tiene usuarios), de este modo:
#groupdel amigos
Realmente lo que estamos haciendo con estos comandos es borrar las líneas correspondientes que se hayan en /etc/passwd y /etc/group como vimos anteriormente.
Para cambiar el directorio HOME del usuario o cambiar su grupo principal, usaremos el comando "usermod", con los modificadores:
#usermod -d /home/profesores/manuel -m sirve para cambiar el directorio HOME del usuario a /home/profesores/manuel (-d) y mover el contenido del antiguo directorio al nuevo (-m)
#usermod -g profesores manuel cambia el grupo principal del usuario manuel a profesores
Puesto que todos los usuarios pueden pertenecer a varios grupos, podemos usar el comando "adduser" que vimos anteriormente para incluir a un usuario en nuevos grupos. Para ello el usuario a modificar y el grupo a asignar deben existir previamente. Si por ejemplo queremos incluir el usuario manuel en el grupo profesores, lo haríamos así:
#sudo adduser manuel profesores
Y podríamos comprobar que esté correcto ejecutando:
#cat /etc/group
Donde nos aparecería "manuel" en la cuarta columna de la línea en que está registrada el grupo "profesores".
Hay que tener en cuenta que "sudo" es un grupo inicial en Linux, donde por defecto se incluye el usuario que creamos al principio cuando instalamos el sistema operativo. Si queremos que un usuario pueda ejecutar el comando "sudo", debemos incluirlo con el comando "#sudo adduser manuel sudo".
Para cambiar el usuario propietario de un fichero y/o directorio emplearemos el comando "chown" y usaremos el modificador "-R" para cambiarlo con su árbol:
#chown -R virginia /home/manuel/archivo.odt con este comando el nuevo usuario propietario de "archivo.odt" sería ahora "virginia"
Si queremos cambiar el grupo propietario, haríamos lo mismo que en el caso del cambio de usuario pero con el comando "chgrp" en lugar de "chown".
Recuerda que podemos consultar usuarios y grupos si no nos acordamos listando con "ls -l".
3. Montaje de dispositivos de almacenamiento
En Linux (continuamos en todo momento hablando de Ubuntu más concretamente) para poder utilizar cualquier dispositivo de almacenamiento, debemos montarlo previamente.Los dispositivos se encuentran en el directorio /dev (device).
Así, tendremos en dicho directorio los dispositivos:
/dev/sda : Primer disco.
/dev/sdb : Segundo disco.
/dev/sdn : N disco.
/dev/sd1 : Primera partición primaria.
/dev/sd2 : Segunda partición primaria.
/dev/sd3 : Tercera partición primaria.
/dev/sd4 : Cuarta partición primaria.
/dev/sd5 : Primera partición lógica.
/dev/sdm : M partición lógica.
/dev/fd0 : Disquetera.
/dev/sr0 : CD/ROM ó DVD.
Observamos que a partir del cuarto "sd" las particiones referenciadas son las lógicas. Por otro lado, si tuviésemos varias disqueteras o varias lectoras de DVD, aparecerían como se ha detallado cambiando el número asociado.
Además de estos dispositivos, se irán creando referencias según añadamos otros nuevos.
Si por ejemplo queremos comprobar los dispositivos (discos, particiones) de que disponemos, ejecutaríamos el comando:
ls -l /dev/sd*
Y una posible salida sería:
ls -l /dev/sd*
Y una posible salida sería:
brw-rw---- 1 root disk 8, 0 feb 12 00:00 /dev/sda
brw-rw---- 1 root disk 8, 1 feb 12 00:00 /dev/sda1
brw-rw---- 1 root disk 8, 2 feb 12 00:00 /dev/sda2
brw-rw---- 1 root disk 8, 16 feb 12 00:00 /dev/sdb
brw-rw---- 1 root disk 8, 17 feb 12 00:0 /dev/sdb1
Observamos en el ejemplo dos discos: el primero representa el disco duro de la máquina que estamos usando, con sus dos particiones (sda1 y sda2). Aquí no distinguimos cual es la swap. El segundo disco es un disco duro externo que a su vez tiene una partición (sdb1).
Mientras que en Windows las particiones se montan en letras (c:\, d:\... etc), en Linux usamos un único árbol de directorios: "/".
Los dispositivos de almacenamiento se montan automáticamente en el directorio "/media".
En ocasiones, tendremos que montarlos de forma manual (por ejemplo si queremos crear particiones posteriores a la instalación). En estos casos, donde se recomienda montar es en el directorio "/mnt" o también llamado "mount".
En Linux los sistemas de archivo en una unidad lógica son ext2, ext3 y ext4. Además, podemos encontrar msdos (FAT16), vfat (FAT32), NTFS e ISO9660 (CD/ROM).
Para montar un dispositivo, previamente debe existir el punto de montaje donde se va a establecer. El punto de montaje no es otra cosa que el directorio de destino. El comando que usaremos es:
#mount dispositivo punto_montaje
Si por ejemplo queremos montar la primera partición lógica del disco en la carpeta "juegos", lo haríamos con:
#sudo mkdir /mnt/juegos (creamos el punto de montaje)
#sudo mount /dev/sdc5 /mnt/juegos
Si queremos montar un CD de juego en la carpeta juego dentro de "/mnt", estableciendo además el sistema de ficheros, lo haríamos así (añadiendo el modificador "-t"):
#sudo mkdir /mnt/juegos
#sudo mount -t iso9660 /dev/sr0 /mnt/juegos
Esta opción suele usarse por seguridad o cuando el comando no determina de forma automática el sistema de ficheros.
Para consultar los dispositivos montados, emplearemos el comando "df". Este comando nos muestra los dispositivos montados así como el espacio total, el espacio ocupado y el espacio libre. A este comando podemos añadirle también modificadores, como "-h" por ejemplo, que nos da la información descrita anteriormente marcando además las unidades.
Para desmontar un dispositivo emplearemos el comando "umount". Esta acción es totalmente necesaria antes de desconectar un dispositivo del ordenador, ya que de lo contrario podríamos cortar procesos de escritura y el sistema lanzarnos errores.
Realmente podemos desmontar un dispositivo o un punto de montaje. Por ejemplo si queremos desmontar el CD juegos que montamos anteriormente usaríamos:
#umount /dev/sr0 ó #umount /mnt/juegos
Cada vez que iniciamos el equipo, tenemos que volver a montar los dispositivos uno a uno. Por ello, existe la opción de añadir líneas a "/etc/fstab" para que hayan dispositivos que se monten automáticamente al iniciar el sistema.
En el fichero nombrado, podemos añadir una línea por cada dispositivo que queramos que se monte de la siguiente manera:
#sudo nano /etc/fstab
/dev/sdb5 /mnt/juegos ntfs user, rw 0 0
Con esto, estamos añadiendo la línea "/dev/sdb5 /mnt/juegos ntfs user, rw 0 0" a "/etc/fstab". En adelante (a no ser que volvamos a borrar dicha línea), se montará siempre la primera partición lógica del disco en el que nos encontremos, formateada con sistema ntfs.
El resto de la información determina que puede ser usada por cualquier usuario, para escribir y leer sin copia de seguridad ni comprobación de errores.
Este fichero es muy útil y podemos ampliar información en:
4. Gestión de particiones
A continuación hablaremos de fdisk, ya que es la herramienta nativa de Linux para particiones. Esta herramienta tan sólo necesita una interfaz de texto, lo que permite que se acceda con facilidad en remoto y se use en equipos sin entorno gráfico basados en la nube.
Si ejecutamos "fdisk /dev/sda" abriremos el programa fdisk para administrar las particiones. Una vez accedamos, pulsamos "m" y nos facilitará (entre otras) las opciones:
m Con la que veremos las distintas opciones disponibles.
p Con la que veremos las particiones actuales disponibles.
n Con la que podremos añadir una nueva partición.
d Con la que podremos borrar una partición existente.
w Con la que podremos guardar las modificaciones que hayamos hecho y salir.
Además, podemos emplear fdisk sin entrar al programa, por ejemplo con "fdisk -l" para mostrar la información en pantalla de todas las particiones que hayan en el equipo sean del disco que sea o con "fdisk -l /dev/sdn" si queremos ver las particiones en el disco "n".
Para formatear una partición (previamente creada) emplearemos el comando "mkfs". En Linux es necesario reiniciar el equipo y formatear una partición tras ser creada, de lo contrario no podremos usarla.
Si queremos por ejemplo formatear la partición 5 con formato ntfs, emplearemos el comando:
#mkfs -t ntfs /dev/sda5
Si no establecemos el formato con "-t formato", se empleará por defecto el "ext3".
Podemos ampliar información sobre la gestión con fdisk pinchando aquí.
5. Gestión de permisos
En Linux gestionamos permisos para tres grupos de usuarios, que son:1º Usuario: Permisos correspondientes al usuario propietario del fichero.
2º Grupo: Permisos correspondientes al grupo propietario del fichero, sin incluir al propietario (que puede o no pertenecer al grupo).
3º Permisos correspondientes al resto de usuarios.
Así, cuando listamos con "ls -l" comprobamos en la columna de información de permisos de usuario que, que si por ejemplo un fichero tiene permisos para todos, aparecería "rwxrwxrwx".
Los permisos en dicha columna se muestran como tres grupos (uno por cada uno de los definidos anteriormente) que tienen tres caracteres cada uno.
El significado de los permisos de ficheros responde a:
r : Permiso de lectura
w : Permiso de escritura
x : Permiso de ejecución
- : Sin permiso
Por ejemplo, si listamos "ls -l" y obtenemos la siguiente línea:
- r w -r - - - - - 1 manuel profesores 50 2020-02-12 00:00 archivo.odt
Significa que el usuario propietario es "manuel" y sus permisos son lectura y escritura (r w -), pero no ejecución. El grupo propietario es "profesores" y sus componentes sólo pueden leer el fichero (r - -). El resto de usuarios no pueden leer, escribir ni ejecutar (- - -).
En Windows los permisos son acumulativos, no así en Linux. Si "profesores" tuviese permiso para ejecutar, "manuel" seguiría sin tenerlos por cómo se han definido dichos permisos.
Además, en Linux los archivos pueden no tener extensión, por lo que es muy importante el permiso de ejecución.
El significado de los permisos de directorios responde a:
r : Permite listar el contenido del directorio
w : Permite crear o borrar entradas en el directorio
x : Permite acceder a las entradas
Generalmente "r" y "x" van relacionadas por lógica, ya que no tiene sentido permitir listar un directorio que no permite cambiar a él y viceversa.
Para cambiar los permisos emplearemos el comando "chmod".
Los permisos de un fichero o directorio tan sólo pueden ser cambiados por el superusuario o por el usuario propietario de los mismos y se pueden indicar empleando la notación octal o la notación simbólica.
De tal modo podemos usar de ejemplos:
#chmod 610 archivo.odt : El archivo "archivo.odt" tiene los permisos rw- --x --- y lo hemos indicado con notación octal.
Esto es, que se sustituye cada letra por 1 ó 0 y asignamos los valores 4 para lectura, 2 para escritura o 1 para ejecución. Así rw- sería 1 1 0 y a su vez 4 2 0. Al sumar este último valor nos daría 6, que es el primer valor de permiso indicado en el comando.
#chmod o+w /home/manuel/juegos : De este modo se da con notación simbólica permisos al resto de usuarios para escritura sobre el fichero "juegos".
Para ello, se usa un patrón en el que:
1º Las categorías a modificar llevan: "u" (para el propietario), "g" (para el grupo), u "o" (para el resto de usuarios).
2º "-" Para retirar permisos, "=" para dejarlos igual o "+" para añadir permisos.
3º Las abreviaturas de los permisos "r", "w" y "x".
5. Gestión de procesos
El arranque en un equipo con Linux montado comienza como en cualquier otro equipo: encendemos y se inicia la BIOS (que detecta el hardware del sistema) que carga el gestor de arranque.
Antes de seguir leyendo, te recomiendo echar un vistazo a este artículo que habla de la diferencia entre GNU/Linux y Linux: https://www.xataka.com/basics/cual-es-la-diferencia-entre-linux-y-gnu-linux. Por ahora, soy de los que usa los términos indistintamente salvo en determinadas ocasiones muy puntuales.
El gestor de arranque de Linux se llama GRUB. Este, accede al directorio /boot (en el caso de iniciar un sistema GNU/Linux) donde carga el kernel y ejecuta el proceso "init". Este proceso se encarga de iniciar todos los servicios para que el sistema funciones, por lo que tiene PID1.
El servicio "systemd" (hay distribuciones, sobretodo antiguas, que usan "Unix System V) inicia el proceso "kthreadd" (PID2) que gestiona el resto de servicios relacionados con el inicio del sistema.
De ahí en adelante, comenzamos a tener procesos hijos, nietos, biznietos... del "init" o del "kthreadd".
Para listar los procesos vivos (que están en activo, en espera o bloqueados) empleamos el comando "ps".
Si ejecutamos el comando "ps -ef", obtendremos, por orden, información bajo las columnas:
1º UID: Usuario que ha ejecutado el proceso.
2º PID: Identificador del proceso, siendo cada no correlativo y no apareciendo en el caso que se describe ahora los terminados.
3º PPID: PID del proceso padre.
4º C: Porcentaje de uso de CPU para el proceso.
5º STIME: Hora a la que se ha ejecutado el proceso.
6º TTY: Terminal o consola donde se ha ejecutado el proceso.
7º TIME: Tiempo que ha empleado el procesador para ejecutar el proceso.
8º CMD: Comando o nombre del proceso ejecutado.
Para terminar un proceso y liberar memoria, se utiliza el comando:
$ kill -9 PID
La señal por defecto para ejecutar el kill es la 15. Al poner -9 estamos usando la señal 9, que es más potente que la 15 y nos da mayores garantías de que se finalice.
Para más información sobre las señales asociadas al comando "kill" podemos lanzar "$ man kill" o consultar Wikipedia.
Para enviar un carácter (o secuencia de caracteres) de forma infinita, empleamos el comando "yes". Si ejecutamos "$ yes hola", devolverá hola infinitamente o hasta que lo detengamos con Ctrl + C.
Si por ejemplo empleamos el comando "$ yes > archivo.txt" y no paramos el proceso, acabaremos llenando la partición. Antiguamente se usaba para automatizar las respuestas en procesos por ejemplo.
Para ordenar los procesos por consumo de recursos emplearemos el comando "top".
Para visualizar las prioridades asignadas a los procesos usamos "ps -ef" ó "ps -efl" por ejemplo y observamos la columna "NI". Las prioridades van desde -20 (máxima) hasta 19 (mínima).
Para ejecutar un proceso con una prioridad concreta empleamos "nice [- n prioridad] comando".
Este comando tiene por defecto la asignación de prioridad 10. Además cualquier usuario puede usar el comando "nice", pero sólo el superusuario puede asignar valores negativos. Así, si queremos asignar la prioridad -10 al proceso "ejemplo", usaríamos:
#nice -n -10 ejemplo
Para cambiar la prioridad a un proceso en ejecución usamos :
$ renice 5 -p 1234
Si no se especifica prioridad alguna por defecto se establece en 0 y los usuarios pueden emplear "renice" para bajar la prioridad. Sólo el superusuario puede usar el comando para subir la prioridad.
6. Información y registro del sistema
Para comprobar la información del sistema, podemos usar el comando "uname". Este comando nos permite por ejemplo saber la versión del kernel instalada (usando el modificador "-r") o conocer la información sobre el Linux que tenemos instalado (usando el modificador "-a") con su kernel, el nombre del equipo y si la versión es de 32 bits o 64 bits.
Recordemos que el kernel o núcleo es independiente de la distribución de Linux (yo uso Ubuntu por ejemplo). Es importante por ejemplo saber la versión mínima del kernel requerida cuando adquirimos nuevo hardware.
Para mostrar información sobre la memoria principal (RAM) usamos el comando "free". Con este comando sabremos la memoria principal, la memoria de intercambio total, la utilizada y la libre.
Para comprobar la información del procesador (núcleos, velocidad, modo de operación... etc) empleamos el comando "lscpu".
Para obtener información sobre las particiones montadas empleamos el comando "df". Esta instrucción nos informa sobre el espacio total, el espacio libre y el espacio utilizado por los dispositivos y/o particiones montadas. El modificador "-h" aporta las unidades de medición en megas y gigas, si no lo usamos aparece en kilobytes.
Para comprobar la información de los directorios disponemos del comando "du". Este comando nos muestra la información sobre el espacio usado por un directorio y sus subdirectorios en Kb. Para ver sólo el directorio (sin subdirectorios) usamos el modificador "-s" y para ver la información en Mb ó Gb usamos el modificador "-h".
Cada vez que iniciamos el equipo se crea el directorio "/proc", que se carga en la memoria principal (RAM). En este directorio podemos consultar la información de cada proceso, así como la información sobre el procesador ("cat /proc/cpuinfo") y la información de memoria ("cat /proc/meminfo").
Para cada PID se crea una carpeta ("/proc/PID") donde podemos consultar su propia información.
Si queremos indagar un poco más sobre el directorio "/proc" puedes pinchar aquí.
Cada vez que se inicia el ordenador, se escriben los archivos "log" (de igual manera que sucede en Windows). Estos son archivos de texto plano que registran todo lo que va sucediendo en el sistema y en Linux, el directorio de registros es "/var/log".
Dentro de dicha carpeta, suele crearse una carpeta por cada servicio donde se guardan sus archivos "log".
Todos los eventos desde que se instaló GNU/Linux se guardan en "/var/log/syslog". Puesto que recoge todo lo que va sucediendo en el sistema, se suele comprobar tan sólo el registro de las últimas líneas (usando el comando "tail").
7. Programación de tareas
La programación de tareas en Linux se efectúa con "cron", que se compone de dos elementos: el elemento "cron" (demonio, un ejecutable que está activo en todo momento) y el archivo de configuración "/etc/crontab".
Si ejecutamos el comando:
ps -ef | grep cron
Podremos entre los procesos en ejecución el de "cron". En este caso hemos filtrado con "grep" (equivalente a "| find" en Windows) para obtener sólo las líneas en que aparece "cron".
Para programar tareas en Linux, tan sólo tenemos que añadir líneas al archivo "/etc/crontab".
Esto, lo podemos hacer desde un editor o empleando el comando "nano /etc/crontab", teniendo como ventaja este último que no necesita privilegios de superusuario. Esto es, porque Linux automáticamente configura esta tarea para que se ejecute con los permisos concretos del usuario.
La primera vez que ejecutemos "crontab -e" (usar un editor) se nos solicitará que elijamos el editor a utilizar. En nuestro caso como hemos comentado, emplearemos el comando "nano".
Si quisiéramos por ejemplo que se ejecute el script "ejemplo.sh" todos los miércoles a las 09.00 h, añadiríamos la línea:
00 9 * * 3 /home/manuel/ejemplo.sh
Donde primero estaríamos marcando los minutos, luego las horas (en formato 24 h), día del mes (hemos usado un comodín para que cuente el día sea cual sea), mes (comodín) y el día de la semana (de domingo a sábado, 0 a 6).
En la explicación hemos nombrado el uso de "comodines". Pues bien, para la notación, estos pueden ser:
* : Cualquier valor
1-3 : Valores 1, 2 y 3
1,3 : Valores 1 y 3
*/3 : Cada 3
Por ejemplo, si queremos que el ordenador se apague cada día a las 23.00 h, añadiríamos la línea:
00 23 * * * poweroff
Por ejemplo, si queremos que se haga una copia de seguridad a un archivo comprimido para el HOME cada cinco días a las 09.00 h en el propio HOME:
00 9 /5 * * tar -cvzf /root/home.tar.gz /home/*
Para comprobar las tareas programadas del usuario "manuel" usaremos el comando "crontab -l -u manuel".
Para eliminar las tareas programadas del usuario "manuel usaremos el comando "crontab -r -u manuel"
Actualmente, la mayoría de versiones de Linux disponen de los directorios cron.hourly, cron.daily, cron.weekly y cron.monthly.
Las líneas que añadamos a estos directorios, se ejecutarán una vez cada hora, día, semana o mes según el que usemos.
Puedes obtener más información al respecto pinchando aquí.
Si nos fijamos, los scripts en Linux actúan de forma similar a los archivos por lotes en Windows. En windows deben tener la extensión ".bat" y en Linux, la extensión no importa siempre que tengan los permisos de ejecución.
Aunque como hemos dicho, en Linux las extensiones no son necesarias, se suelen poner ".sh" a los script para diferenciarlos.
Los scripts también son llamados Shell-script ó guiones Shell, ya que realmente son guiones interpretados por el terminal.
Para indicar que el script lo va a interpretar la shell de bash, registramos como primera línea del mismo "!/bin/bash".
Aunque la programación de scripts la explicaré en otras publicaciones, podemos tomar como ejemplo este en el que se crea un directorio, se redirecciona contenido a un fichero dentro del directorio, se limpia la pantalla, se muestra el listado del directorio y el contenido del directorio:
nano ejemplo.sh (para escribir contenido en el script, si quisiéramos consultarlo emplearíamos "cat)
#!/bin/bash
mkdir /home/manuel/carpeta
echo linea1 del fichero.txt > /home/manuel/carpeta/fichero.txt
clear
ls -l /home/manuel/carpeta
echo Se muestra el contenido del fichero.txt
cat /home/manuel/carpeta/fichero.txt
Espero que os haya sido de utilidad. Con el tiempo iré revisando, modificando, adaptando y sumando contenido a la entrada
